| Distribuzione lognormale |
|---|
Funzione di densità di probabilità

|
Funzione di ripartizione
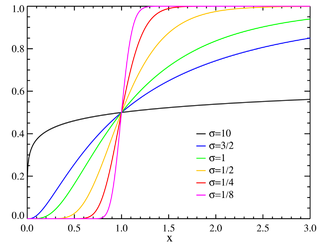
|
| Parametri | 

|
|---|
| Supporto | 
|
|---|
| Funzione di densità | 
|
|---|
| Funzione di ripartizione | 
|
|---|
| Valore atteso | 
|
|---|
| Mediana | 
|
|---|
| Moda | 
|
|---|
| Varianza | 
|
|---|
| Indice di asimmetria | 
|
|---|
| Curtosi | 
|
|---|
| Entropia | 
|
|---|
| Manuale |
In teoria delle probabilità la distribuzione lognormale, o log-normale, è la distribuzione di probabilità di una variabile aleatoria  il cui logaritmo
il cui logaritmo  segue una distribuzione normale.
segue una distribuzione normale.
Questa distribuzione può approssimare il prodotto di molte variabili aleatorie positive indipendenti.
Viene utilizzata anche in matematica finanziaria.
La variabile aleatoria  segue la distribuzione lognormale
segue la distribuzione lognormale  se e solo se
se e solo se  segue la distribuzione normale
segue la distribuzione normale  .
.
La sua funzione di densità di probabilità è
 per
per  .
.
La funzione di ripartizione della distribuzione lognormale è

dove  è la funzione di ripartizione della distribuzione normale ed
è la funzione di ripartizione della distribuzione normale ed  è la funzione degli errori.
è la funzione degli errori.
I momenti semplici della distribuzione possono essere dedotti dalla funzione generatrice dei momenti della distribuzione normale di
![{\displaystyle \mu _{n}(X)=E[X^{n}]=E[e^{nN}]=g_{N}(n)=e^{n\mu +n^{2}{\frac {\sigma ^{2}}{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79090d452db393f9cc4a71b856e8ea3f092f7084) .
.
In particolare si trovano
![{\displaystyle E[X]=e^{\mu +{\frac {\sigma ^{2}}{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be71b061c89ac6f9745690f9349bd50e5d294907)
![{\displaystyle {\text{Var}}(X)=E[X^{2}]-E[X]^{2}=e^{2\mu }(e^{2\sigma ^{2}}-e^{\sigma ^{2}})=e^{2\mu +\sigma ^{2}}(e^{\sigma ^{2}}-1)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/947254d1d8c0f360206bdfdc8a95cad862ebb062) .
.
I parametri  possono essere ricavati dalla speranza e dalla varianza, utilizzando la relazione
possono essere ricavati dalla speranza e dalla varianza, utilizzando la relazione ![{\displaystyle {\tfrac {{\text{Var}}(X)}{E[X]^{2}}}=e^{\sigma ^{2}}-1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2934f6c1bf18f1c1464b1d84d599da2f5e33ee5e) .
.
Gli indici di asimmetria e curtosi sono
 e
e  .
.
La moda della distribuzione è .
La mediana è  e si trova immediatamente tramite la mediana
e si trova immediatamente tramite la mediana  di :
di :  .
.
Se è una variabile aleatoria con distribuzione lognormale  allora
allora
- segue la distribuzione normale .
Per ogni trasformazione lineare (invertibile)
 segue ancora una distribuzione normale
segue ancora una distribuzione normale 
 segue una distribuzione lognormale
segue una distribuzione lognormale  .
.
In particolare seguono una distribuzione lognormale
- i multipli scalari
 ,
,
- le potenze

- e l'inverso
 di .
di .
Per la definizione di distribuzione lognormale non è importante che venga scelto il logaritmo naturale, ovvero la base e: due distinti logaritmi  e
e  differiscono soltanto di un fattore
differiscono soltanto di un fattore  .
.
La distribuzione lognormale svolge un ruolo simile a quello della distribuzione normale, la quale può fornire un'approssimazione per la somma di "molte" variabili aleatorie indipendenti  aventi una stessa distribuzione (teorema del limite centrale). Se le
aventi una stessa distribuzione (teorema del limite centrale). Se le  sono positive allora la distribuzione lognormale può fornire un'approssimazione per il loro prodotto (così come la distribuzione normale può fornire un'approssimazione per la somma dei loro logaritmi,
sono positive allora la distribuzione lognormale può fornire un'approssimazione per il loro prodotto (così come la distribuzione normale può fornire un'approssimazione per la somma dei loro logaritmi,  ).
).


 Wikimedia Commons contiene immagini o altri file su Distribuzione lognormale
Wikimedia Commons contiene immagini o altri file su Distribuzione lognormale