Audio forense
L'audio forense è il campo della scienza forense che si occupa dell'acquisizione, dell'analisi e della valutazione delle registrazioni sonore che possono essere presentate come prove ammissibili in un tribunale o in un'altra sede ufficiale.[1][2][3][4]
Le prove audio forensi possono provenire da un'indagine penale condotta dalle forze dell'ordine o come parte di un'inchiesta ufficiale su un incidente, una frode, un'accusa di calunnia o un altro incidente civile.[5]
Gli aspetti principali dell'audio forense sono la determinazione dell'autenticità delle prove audio, il miglioramento delle registrazioni audio per migliorare l'intelligibilità del parlato e l'udibilità dei suoni di basso livello, l'interpretazione e la documentazione delle prove sonore, come l'identificazione dei parlanti, la trascrizione dei dialoghi e la ricostruzione delle scene del crimine o degli incidenti e delle tempistiche.[2]
La moderna audio forense fa ampio uso dell'elaborazione digitale del segnale, mentre l'uso precedente di filtri analogici è ormai obsoleto. Tecniche come il filtraggio adattivo e le trasformate discrete di Fourier sono ampiamente utilizzate. I recenti progressi nelle tecniche di audio forense includono la biometria vocale e l'analisi della frequenza della rete elettrica.[6]
Storia[modifica | modifica wikitesto]
La possibilità di eseguire analisi audio forensi dipende dalla disponibilità di registrazioni audio effettuate al di fuori dei confini di uno studio di registrazione. I primi registratori portatili a nastro magnetico sono apparsi negli anni Cinquanta e ben presto questi dispositivi sono stati utilizzati per ottenere registrazioni clandestine di interviste e intercettazioni, oltre che per registrare gli interrogatori.[4]
Il primo caso legale che ha invocato le tecniche audio forensi nei tribunali federali degli Stati Uniti è stato il caso United States v. McKeever, che ha avuto luogo negli anni Cinquanta.[7] Per la prima volta, al giudice del caso McKeever fu chiesto di determinare l'ammissibilità legale della conversazione registrata che coinvolgeva l'imputato.[8]
Il Federal Bureau of Investigation (FBI) degli Stati Uniti ha iniziato a implementare l'analisi forense dell'audio e il miglioramento dell'audio all'inizio degli anni Sessanta.[4]
Il campo dell'audio forense si è affermato principalmente nel 1973, durante lo scandalo Watergate. Un tribunale federale incaricò un gruppo di ingegneri audio di indagare sulle lacune dei nastri del Watergate, registrazioni segrete effettuate dal Presidente degli Stati Uniti Richard Nixon durante il suo mandato. L'indagine ha rilevato che nove sezioni separate di un nastro fondamentale erano state cancellate. Il rapporto diede origine a nuove tecniche di analisi del nastro magnetico.[6]
Autenticità[modifica | modifica wikitesto]
Una registrazione audio digitale può presentare molte sfide per la valutazione dell'autenticità.[9] L'analisi dell'autenticità delle registrazioni audio digitali si basa sulle tracce lasciate all'interno della registrazione durante il processo di registrazione e da altre operazioni di editing successive. Il primo obiettivo dell'analisi è individuare e identificare quali di queste tracce possono essere recuperate dalla registrazione audio e documentarne le proprietà. In una seconda fase, le proprietà delle tracce recuperabili vengono analizzate per determinare se supportano o contrastano l'ipotesi che la registrazione sia stata modificata.
Per accedere all'autenticità delle prove audio, l'esaminatore ha bisogno di diversi tipi di osservazione, come ad esempio: controllare la capacità di registrazione, il formato della registrazione, rivedere la cronologia dei documenti, ascoltare l'intero audio.[10]
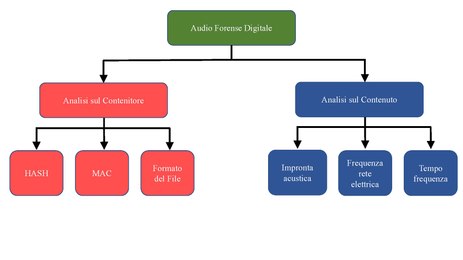
Le tecniche per controllare l'integrità di un segnale audio digitale si possono dividere in due categorie principali[8]:
- Tecniche basate sul Contenitore
- Tecniche basate sul Contenuto
Analisi del Contenitore[modifica | modifica wikitesto]
L'analisi del contenitore consiste nel calcolo di funzioni di Hash, analisi del MAC e del formato del file.[8]
- Analisi Hash: Una stringa di caratteri univoca viene ricavata dai bit e dai byte del file audio e calcolata da una funzione hash di origine matematica. Queste funzioni possono essere utili per verificare che non siano state apportate modifiche a un file dal momento in cui è stato calcolato l'HASH alla successiva istanza di calcolo dell'HASH.
- MAC time stamps: Utilizzando le marche temporali MAC, l'esaminatore può rilevare la data e l'ora di creazione del file e delle sue modifiche, nonché l'ora dell'ultimo accesso. Le marche temporali MAC sono generate dall'interlock del sistema digitale, che però può essere corrotto da operazioni di copia/trasferimento o da operazioni di modifica.
- Formato del File: Analisi di alcuni parametri audio incorporati nel formato audio (codec, frequenza di campionamento, profondità di bit, ecc.).
- Header: Gli scienziati possono rilevare una modifica nella registrazione utilizzando le informazioni di intestazione del formato del file. A seconda del dispositivo e della marca, possono essere presenti informazioni sul modello, sul numero di serie, sulla versione del firmware, sull'ora, sulla data e sulla durata della registrazione (determinata dalle impostazioni dell'orologio interno). È utile annotare le marche temporali e confrontarle con la data e l'ora dichiarate dai registranti in merito alla data di creazione del file.[11]
- Dati Esadecimali: I dati digitali grezzi del file possono contenere informazioni utili che possono essere esaminate in un lettore esadecimale con un visualizzatore di caratteri ASCII. Possono essere visualizzati gli indirizzi dei blocchi delle informazioni audio, i titoli dei software esterni (se presenti), le operazioni di post-elaborazione e altre informazioni utili.[12]
Analisi del contenuto[modifica | modifica wikitesto]
L'analisi del contenuto è la parte centrale del processo di analisi forense digitale e si basa sul contenuto del file audio per trovare tracce di manipolazione e operazioni di elaborazione anti-forense. Le tecniche forensi audio basate sul contenuto possono essere suddivise nelle seguenti categorie:
- Frequenza della rete elettrica
- Impronta acustica dell'ambiente
Frequenza della rete elettrica[modifica | modifica wikitesto]
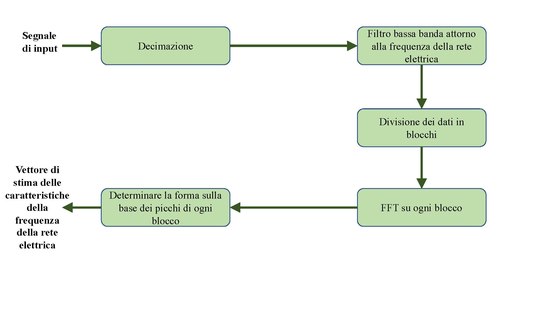
La frequenza della rete elettrica è una delle analisi forensi audio più affidabili e robuste.[8]
Tutti i dispositivi di registrazione digitale sono sensibili alla frequenza indotta dell'alimentazione a 50 o 60 Hz, che a sua volta fornisce una firma di forma d'onda identificabile nella registrazione. Questo vale sia per le unità alimentate dalla rete elettrica che per i dispositivi portatili quando questi ultimi vengono utilizzati in prossimità di cavi di trasmissione o di apparecchiature alimentate dalla rete elettrica.[13]
Il vettore di caratteristiche della frequenza della rete elettrica è ottenuto utilizzando un filtraggio passa-banda tra i 49 e i 51 Hz, senza ricampionare il file audio, per separare la forma d'onda della frequenza della rete elettrica dalla registrazione originale. I risultati vengono quindi tracciati e analizzati rispetto al database fornito dal fornitore di energia per provare o smentire l'integrità della registrazione, fornendo così un'autenticazione probatoria e scientifica del materiale in analisi.[13]
Impronta acustica dell'ambiente[modifica | modifica wikitesto]
Una registrazione audio è solitamente una combinazione di più segnali acustici, quali: sorgente diretta, segnali indiretti o riflessioni, sorgenti secondarie e rumore ambientale. I segnali indiretti, le sorgenti secondarie e il rumore ambientale sono utilizzati per caratterizzare un ambiente acustico.[4] Il lavoro difficile consiste nell'estrapolare gli spunti acustici dalla registrazione audio.
L'identificazione dinamica dell'ambiente acustico può essere calcolata utilizzando una stima della riverberazione e del rumore di fondo.[8]
Miglioramento dell'audio[modifica | modifica wikitesto]
Il miglioramento dell'audio è il processo forense di affinamento del file audio, che rimuove e pulisce il rumore indesiderato da una registrazione altrimenti incomprensibile.[2]
Gli scienziati forensi cercano di rimuovere questi rumori senza intaccare le informazioni originali presenti nel file audio. Il miglioramento permette di ottenere una migliore intellegibilità del file, in modo da provare o smentire la partecipazione di un individuo in un crimine.[8]
Il fulcro dell'analisi di miglioramento dell'audio consiste nell'individuare i problemi di rumore e nell'estrarlo dal file originale, perché, se il rumore può essere invertito in qualche modo, può essere sfruttato e studiato per consentirne la successiva rimozione o attenuazione.[13]
Gli obiettivi del miglioramento dell'audio forense sono:
- Aumentare l'accuratezza delle trascrizioni
- Ridurre l'affaticamento degli ascoltatori
- Aumentare l'intelligibilità del parlato
- Aumentare l'SNR
La prima fase del processo di miglioramento dell'audio è l'ascolto critico: la registrazione completa viene esaminata, al fine di formulare una valida strategia forense. La creazione di cloni della registrazione audio è essenziale, poiché non si lavora mai sulla registrazione master per avere il file originale e poterlo confrontare con esso. Durante l'intero processo di miglioramento, l'originale viene costantemente confrontato con la registrazione originale non elaborata, evitando così un'elaborazione eccessiva e prevenendo i problemi che potrebbero essere sollevati in seguito durante il processo. Seguire le linee guida e le procedure di lavoro consente a diversi specialisti di ottenere gli stessi risultati utilizzando la stessa elaborazione.[13]
Possiamo dividere i suoni di disturbo in due categorie: rumore stazionario o rumore variabile nel tempo.
Il rumore stazionario ha un carattere costante, come un fischio, un ronzio, un rombo o un sibilo continuo. Supponiamo che il rumore stazionario occupi una gamma di frequenze diversa da quella dei segnali di interesse, ad esempio una registrazione vocale con un rimbombo costante nella gamma di frequenze inferiori a 100 Hz. In questo caso, è possibile applicare un filtro fisso, come un filtro passa-banda, per far passare approssimativamente la larghezza di banda del parlato. Di solito la larghezza di banda del parlato va da 250 Hz a 4 kHz.[14]
Se la larghezza di banda del rumore stazionario occupa la stessa gamma di frequenze del segnale desiderato, un semplice filtro di separazione non sarà utile. Tuttavia, è possibile applicare un'equalizzazione per migliorare l'udibilità/intelligibilità del segnale desiderato.[4]
Le sorgenti di rumore variabili nel tempo richiedono generalmente un'elaborazione più complicata rispetto alle sorgenti di rumore stazionarie e spesso non vengono soppresse in modo efficace.[4]
Metodi di miglioramento[modifica | modifica wikitesto]
Il miglioramento dell'audio è realizzato sia nel dominio del tempo, con il controllo automatico del guadagno, sia nel dominio della frequenza, con filtri selettivi di frequenza e sottrazione spettrale.[15]
Controllo automatico del guadagno[modifica | modifica wikitesto]
Il miglioramento nel dominio del tempo di solito comporta la regolazione del guadagno per normalizzare l'inviluppo di ampiezza del segnale audio registrato. In genere si utilizza la tecnica di controllo automatico del guadagno, o la tecnica di compressione/espansione del guadagno, che cerca di raggiungere un livello sonoro costante durante la riproduzione: le porzioni della registrazione riferibili solo al rumore vengono rese più silenziose, i passaggi del segnale a bassa ampiezza vengono amplificati e i passaggi forti vengono attenuati o lasciati così come sono.
Un approccio comune è quello di applicare un noise gate o un processo di squelch al segnale rumoroso. Il noise gate può essere realizzato come un dispositivo elettronico progettato per lo scopo, oppure può essere un software per l'elaborazione con un computer. La porta di rumore confronta il livello di breve durata del segnale in ingresso con una soglia di livello predeterminata. Se il livello del segnale è superiore alla soglia, la porta si apre e il segnale viene lasciato passare, altrimenti se il livello del segnale è inferiore alla soglia, la porta si chiude e il segnale non viene lasciato passare. Il ruolo dell'esaminatore è quello di regolare il livello di soglia in modo che il parlato possa passare attraverso il gate, mentre il segnale di rumore, che si verifica nelle parti di silenzio, viene bloccato. Un noise gate può aiutare l'ascoltatore a comprendere un segnale che viene percepito come meno rumoroso perché il suono di fondo viene escluso durante le pause della conversazione. Tuttavia, il noise gate nella sua versione semplice non può ridurre il livello di rumore e contemporaneamente potenziare il segnale quando entrambi sono presenti contemporaneamente e il gate è aperto.[2]
Esistono poi sistemi di noise gate più avanzati che sfruttano alcune tecniche di elaborazione digitale del segnale per eseguire una separazione di gating in diverse bande di frequenza. Questi sistemi avanzati aiutano l'esaminatore a rimuovere particolari tipi di rumore e sibili presenti nella registrazione audio.[15]
Filtri selettivi in frequenza[modifica | modifica wikitesto]
I filtri selettivi in frequenza sono una tecnica che opera nel dominio della frequenza. Il principio alla base di questa tecnica è quello di migliorare la qualità di una registrazione attenuando selettivamente le componenti tonali dello spettro, come i segnali di ronzio e ronzio legati alla potenza. L'uso di un equalizzatore audio multibanda può anche essere utile per ridurre il rumore fuori banda, pur mantenendo la banda di frequenza di interesse, come la gamma di frequenza del parlato.[15]
Sottrazione spettrale[modifica | modifica wikitesto]
La sottrazione spettrale è una tecnica di elaborazione del segnale digitale in cui lo spettro del rumore a breve termine viene stimato da una porzionedel segnale e quindi sottratto dallo spettro delle porzioni brevi del segnale di ingresso rumoroso. Lo spettro ottenuto dopo la sottrazione viene utilizzato per ricostruire la finestra del segnale di uscita ridotto dal rumore. Il processo continua per le porzioni successivi per creare l'intero segnale di uscita attraverso una procedura di overlap-add.[16]
L'efficacia della sottrazione spettrale si basa sulla capacità di stimare lo spettro del rumore. I metodi di riduzione del rumore più sofisticati combinano i concetti di rilevamento del livello nel dominio del tempo e di sottrazione spettrale nel dominio della frequenza. Vengono utilizzati modelli di segnale e regole aggiuntive per separare i componenti del segnale che molto probabilmente fanno parte del segnale desiderato da quelli che probabilmente sono rumore additivo.[15]
Interpretazione[modifica | modifica wikitesto]
Dopo l'autenticazione e il miglioramento, il file audio esaminato deve essere valutato e interpretato per determinarne l'importanza ai fini dell'indagine.[15]
Ad esempio, nel caso di una registrazione vocale, ciò significa preparare una trascrizione del contenuto audio, identificare i parlanti, interpretare i suoni di sottofondo e così via.[15]
Nel 2009, l'Accademia Nazionale delle Scienze degli Stati Uniti (NAS) ha pubblicato un rapporto intitolato Strengthening Forensic Science in the United States: A Path Forward.[17] Il rapporto era molto critico nei confronti di molte aree della scienza forense, compresa la scienza forense dell'audio, che tradizionalmente si basa su analisi e confronti soggettivi.
L'importanza e l'affidabilità delle prove forensi dipendono da una serie di contributi alle indagini. Un certo livello di incertezza è quasi sempre presente, perché di solito le prove audio forensi vengono interpretate con considerazioni oggettive e soggettive.
Mentre in uno studio scientifico l'incertezza può essere misurata con alcuni indicatori e l'analisi continua può fornire ulteriori approfondimenti in futuro, un esame forense non è solitamente soggetto a revisione continua. Il giudizio deve essere formulato al momento dell'udienza, quindi il tribunale deve soppesare i vari elementi di prova e valutare il livello di dubbio che può esistere.[18]
Note[modifica | modifica wikitesto]
- ^ Phil Manchester, An Introduction To Forensic Audio, su soundonsound.com, Sound on Sound, gennaio 2010.
- ^ a b c d Robert C. Maher, Audio forensic examination: authenticity, enhancement, and interpretation, in IEEE Signal Processing Magazine, vol. 26, n. 2, marzo 2009, pp. 84–94, DOI:10.1109/msp.2008.931080.
- ^ Alexander Gelfand, Audio Forensics Experts Reveal (Some) Secrets, su wired.com, Wired Magazine, 10 ottobre 2007 (archiviato dall'url originale l'8 aprile 2012).
- ^ a b c d e f Robert C. Maher, Principles of forensic audio analysis, Cham, Switzerland, Springer, 2018, ISBN 9783319994536, OCLC 1062360764.
- ^ Robert C. Maher, Lending an ear in the courtroom: forensic acoustics (PDF), in Acoustics Today, vol. 11, Summer 2015, pp. 22–29.
- ^ a b Christopher Williams, Met lab claims 'biggest breakthrough since Watergate', su theregister.com, The Register, 1º giugno 2010. URL consultato il 15 settembre 2021.
- ^ United States District Court, Southern District, New York. (1958). U.S. v. McKeever, 169 F. Supp. 426 (S.D.N.Y. 1958).
- ^ a b c d e f Mohammed Zakariah, Muhammad Khurram Khan e Hafiz Malik, Digital multimedia audio forensics: past, present and future, in Multimedia Tools and Applications, vol. 77, n. 1, 9 gennaio 2017, pp. 1009–1040, DOI:10.1007/s11042-016-4277-2, ISSN 1380-7501.
- ^ E.B. Brixen, Techniques for the authentication of digital audio recordings, in In Proceedings Audio Engineering Society 122nd Convention, Vienna, Austria, 2007.
- ^ BE Koenig, Authetication of forensic audio recordings, in J Audio Eng Soc, vol. 38, 1990, pp. 3-33.
- ^ BE Koenig e DS Lacey, Forensic autheticity analyses of the header data in re-encoded WMA files from small Olympus audio recorders, in J Audio Eng Soc, vol. 60, 2012, pp. 255-265.
- ^ BE Koenig e DS Lacey, Forensic authentication of digital audio recordings., in J Audio Eng Soc, vol. 57, 2009, pp. 662-695.
- ^ a b c d An Introduction To Forensic Audio, su soundonsound.com. URL consultato il 28 giugno 2022.
- ^ Definition: Voice frequency, su its.bldrdoc.gov.
- ^ a b c d e f Robert C. Maher, Overview of Audio Forensics, in Intelligent Multimedia Analysis for Security Applications, vol. 282, pp. 127-144.
- ^ S. Boll, A spectral subtraction algorithm for suppression of acoustic noise in speech, in ICASSP '79. IEEE International Conference on Acoustics, Speech, and Signal Processing, Institute of Electrical and Electronics Engineers, DOI:10.1109/icassp.1979.1170696.
- ^ US National Academy of Sciences (NAS), Strengthening Forensic Science in the United States: A Path Forward (PDF), su ojp.gov.
- ^ Geoffrey Stewart Morrison, Measuring the validity and reliability of forensic likelihood-ratio systems, in Science & Justice, vol. 51, n. 3, 2011, pp. 91–98, DOI:10.1016/j.scijus.2011.03.002, ISSN 1355-0306.
Bibliografia[modifica | modifica wikitesto]
- Robert C. Maher, Principles of forensic audio analysis, Cham, Switzerland, Springer, 2018, ISBN 9783319994536.
- James Zjalic, Digital Audio Forensics Fundamentals, Focal Press, 2020, ISBN 9781000205718.